CDISC 标准(四)——SDTM 数据集详细分类
总结
本笔记的主要内容:
- 介绍 SDTM 标准下的七个大类别,以及主要包括的数据集;
- 梳理两个最重要的数据集:AE(副作用数据集)和 LB(实验室检测结果数据集)。
SDTM 的全称是 SDTM Standard dataset tabulation model,即实验数据标准化的模型,在之前的笔记中有一个概述的介绍。SDTM 标准力图能够尽可能覆盖在临床实验进行过程中所需要收集到的所有数据和相关信息,因此也详细地设计了各种不同分类的大类别和数据集。
在这个分类下,总共包括七个大类别和 44 个数据集。每一种数据集都属于唯一一个类别。七个大类别“SIFEFTR”:
- 特殊目的类:Special Purpose
- 干涉类:Intervention
- 发现类:Findings
- 发现相关类:Findings About
- 事件类:Events
- 实验设计类:Study Trial
- 关系类:Relationship
下面分门别类介绍每一种类型。
特殊目的类 Special Purpose
特殊目的类:包括和实验参与者本人相关的数据,无法归类到其他类别。主要包括以下几个数据集:
- CO:评价数据集,Comments**,医生手写或者补充的文本备注和记录,需要与其他数据集相连接;如果手写的记录超过 CDISC 规定的最长值长度 200 个字符,就需要创建新的 COVAL1,COVAL2 变量保存字符,以此类推,每个变量容纳 200 个字符;
- DM:人口统计学,Demographics,用于保存患者的基础信息,比如患者编号、性别、国籍、种族、实验开始时间等等,在之前的内容中有所记录;
- SV:患者来访数据,Subject Visit
- SE,患者时期元素,Subject Element
- 一个患者在整个临床实验过程中需要来访多次。一般是从 Screen 和纳入开始,之后的来访依次是基线,第一次来访,第二次来访等,直到实验结束。在服用药物过后,因为药物在人体内有残留期,也需要几次患者来访,来观察是否具有副作用和其他治疗效果。
- 患者来访的时间数据都需要记录在 SV 数据集中。每个患者在实验过程中经历的每个时期和元素的时间信息,这些数据被放在 SE 中。
干涉类 Interventions
干涉类主要包括对患者有影响的行为的相关数据,包括以下几个数据集:
- CM:伴随用药 Concomitant and prior medications
- 参加临床实验的患者,如果有其他疾病,需要服用已经上市的药物,就需要在数据集中记录伴随用药的相关信息;如果是和癌症相关的临床实验,可能需要让受试者服用一种统计的抗癌药物,再服用待实验的药物,那么这个统一服用的药物也需要放置在 CM 数据集中;
- CM 数据集存放患者服用的其他药物(非本实验药物)的名称、类别、剂量、计量单位、频率、药物类型(胶囊/饮剂)等数据;
- EX:实验用药 Exposure
- 实验计划中药物的使用情况;
- 根据实验设计来确定,核心变量包括 EXTRT(药物的名称),EXDOSE(药物的剂量),EXDOSU(药物剂量的单位),EXDOSFRQ(药物按此剂量服用的频率) 和 EXDOSFRM(药物的形式,液体/胶囊/含服片);
- EC:实际实验用药 Exposure as Collected
- 实际中**药物的使用情况
- 由 ECOCCUR 变量指定该次是否服药,ECDOSE 记录剂量,ECDOSU 记录剂量单位;
- EC 和 EX 数据集的结构基本相同,实际分析使用 EX 数据集,因为根据实验设计而来的
- PR:过程 Procedures
- 患者治疗和诊断相关的过程
- 比如患者参与心血管相关的临床实验,中间去口腔科诊断并拔了智齿,这个过程无法判断是否与临床实验相关,所以也要记录下来。
- 核心变量:PRTRT,记录做的手术名称
- PRSTDTC,PRENDTC,PRSTDY,PRENDY 分别对应手术开始的日期和结束的日期,以及对应的天数;
- SU:物质使用 Substance Use
- 其他非药物的物质的使用情况,比如最常见的咖啡(含有咖啡因),吸烟、喝酒;
- 主要包括以下几个变量:SUTRT(使用物质的名称,包括 CIGARETTES,COFFEE)、SUCAT(使用物质所属的大类)、SUDOSE(这些物质使用的数量)、SUDOSEU(使用物质的数量单位)、SUDOSFRQ(使用物质的频率)、SUSTAT,SUREASND(数值没有被记录和没有记录的原因)
事件类 Events
事件类,代表计划之外的事件,总共包括 6 个数据集:
- AE:副作用,Adverse Events
- CE:临床事件,Clinical Events
- DS:处置,Disposition
- DV:实验计划偏差,Protocol Deviations
- HO:医疗事件,Healthcare Encounters
- MH:既往药史,Medical History
其中最最重要的是 AE,也就是副作用数据集。
AE 的主要变量包括四种类型:
- 第一类:副作用的名称和类别
- AE 中,每个副作用不仅要求记录它的名称,还需要记录所属的更高级身体组织和系统。基本上原始数据集会提供这些数据,如果需要查询,每个副作用的详细分类信息存在一个名为 MedDRA 的文档之中;
- AETERM(副作用名称)、AEDECOD(副作用标准名称)
- 第二类:属性类变量
- 相当于给每条副作用的属性进行记录,比如 AESEV(副作用严重程度),取值为 3 种,由轻到重分别是 MILD,MODERATE 和 SEVERE;
- AEACN(副作用发生后采取的行动,包括药量减少、暂时停药、退出实验等)、AEOUT(副作用的结果,包括解决中、已解决、甚至患者死亡)、AEREL(副作用是否与药物相关);
- 第三类:评价类变量
- 往往用 Flag 来表示是否满足标量所描述的情况,Y 表示符合,N 表示不符合;
- 比如 AESCONG 表示是否导致了胎儿先天性异常和缺陷;AESDISAB 表示是否导致了残疾,AESDTH 表示是否导致死亡,AESHOSP 表示是否导致住院等;
- 第四类:时间类变量
- AESTDTC 和 AEENDTC 表示副作用开始和结束的时间;
- 对应的 DY 类变量:AESTDY 和 AEENDY;
- AEDUR 表示副作用持续时间的变量。
发现类 Findings
发现类中包括最多数量的数据集。其中,大部分数据集只用于特殊疾病或者药物中,真正常用的发现类数据集如下:
- EG:心电图测试指标**,ECG Test Results
- IE:每名患者纳入排除标准的情况,Inclusion/Exclusion Creterion Not Met
- **LB:血检尿检指标 Laboratory Test Results
- QS:调查问卷 Questionnaires**,在涉及生活质量的实验当中,QS 往往是最重要的数据集之一;
- **VS:记录人体的一些基本信息 Vital Signs,包括身高、体重、脉搏、血压等。
而关于癌症的发现类数据集有下列几项:
- TU:Tumor Identification
- TR:Tumor Results
- RS:Disease Response
发现类数据集一般有如下通用的结构,其中 XX 表示对应的数据集名字:
- 检测的名称:XXTEST;
- 检测名称的标准缩写:XXTESTCD,CDISC 中规定或者药厂自行规定;
- 检测分类:XXCAT,XXSCAT;
- 检测结果和对应的单位:XXORRES,XXORRESU;
- 检测的标准化结果(取国际通用单位):XXSTRESC:字符型结果,XXSTRESN:数值型结果,XXSTRESU:标准储存单位;
- 患者来访的名称和次数:VISIT,VISITNUM(没有前缀);
- 时间类型变量:XXDTC/DY(检测时间和距离实验开始天数),比如 LBDTC 代表记录血检/尿检的检测时间,QSDTC 代表记录问卷填写的检测时间。
发现相关类数据集 Findings About
也算是发现类的一种类型,之所以叫发现相关类是因为收集的数据不像发现类那么标准,主要包括以下两类:
- FA:Findings About,除了 FATEST 以外还有一个 FAOBJ,表示实验的对象
- SR:Skin Response
实验设计类 Trial design
实验设计类记录实验设计相关的内容。这些数据一般都是从统计分析计划的 SAP 中直接获得,查看这些数据集可以帮我们理解实验是如何设计的。主要包括如下 6 个数据集:
- TA:实验分组 Trial Arms
- TD:实验疾病数据 Trial Disease Assessment
- TE:实验时期元素 Trial Elements
- TV:实验来访计划 Trial Visits
- TI:实验纳入排除标准 Trial Inclusion / Exclusion Criteria
- TS:实验总结 Trial Summary
Relationship 关系类
主要包括以下 2 个数据集:
- RELREC:关系数据,比如一个患者的副作用被医生发现是由于伴随用药表引起的,那么应该有一个记录将副作用和伴随用药记录连接起来。
- SUPP:补充数据集,之前讲过,可以用于补充任何一个标准 SDTM 数据集,命名为 SUPP + XX(关联的数据集名字);
其他内容
SUPP 补充数据集
每一个 SDTM 数据集都可以用一个补充数据集,用来存放与主数据集相关的数据;
- 名称是 SUPP + XX(原始数据集名字),比如 LB 对应的就是 SUPPLB;
- 举例:
- SUPPDM 中放置实验人口的 FLAG(包括 ITT,PPROT);
- SUPPAE 放置是否是实验期间副作用和非实验期间副作用的标识 TRTEM;
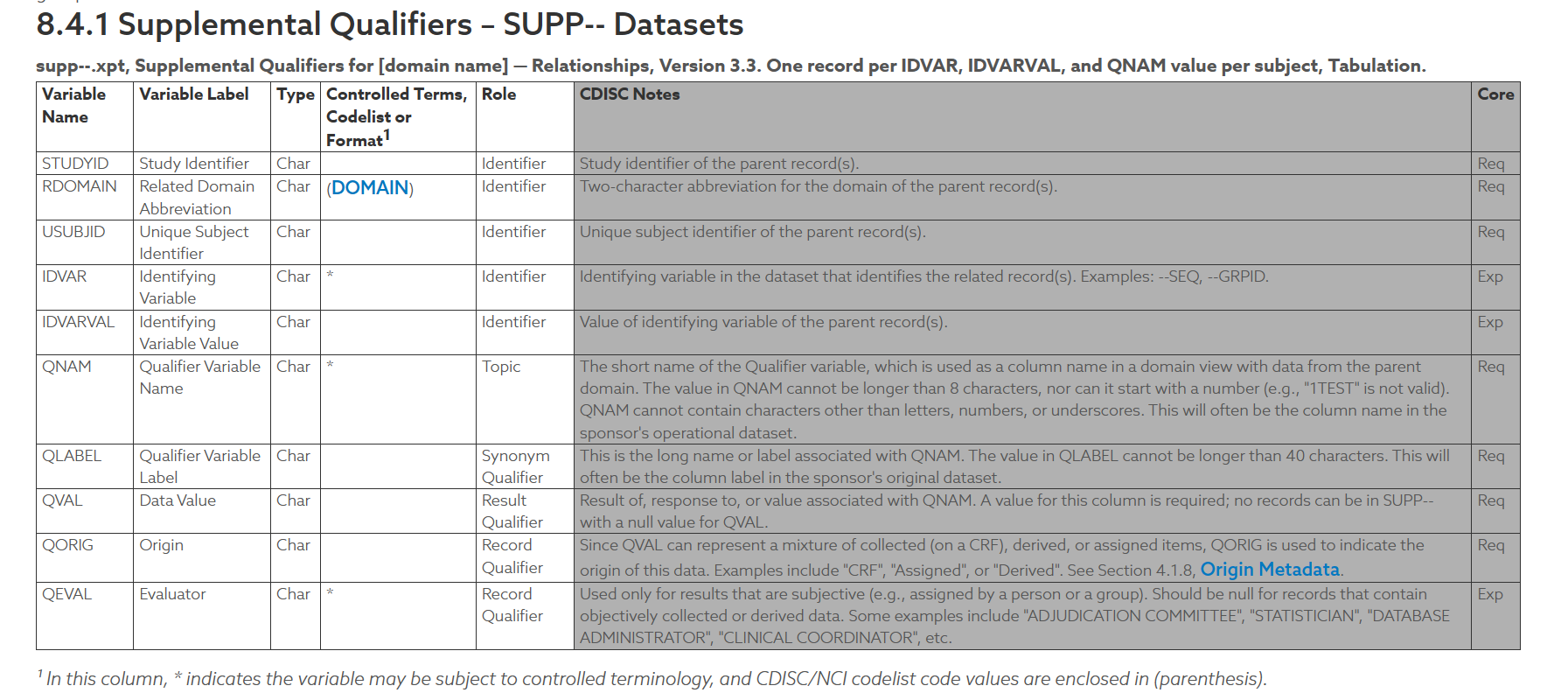
SUPP 数据集下面总共有 10 个变量:
- STUDYID,USUBJID:通用变量,不赘述;
- RDOMAIN:对应的主数据集,举例,如果对应的是 AE,RDOMAIN 值为 AE;
- IDVAR,IDVARVAL:在每名患者有多条记录的时候使用,需要指出对应主数据集的哪条记录,比如如果需要对应 AE 中的 AESEQ,那么 IDVAR 的值就是 AESEQ,IDVARVAL 的值就是对应的记录条数(但需要注意转化为字符型);
- QNAM:描述一下所定义的值是什么意思,但只能使用不长于 8 位数的字符;
- QLABEL:不超过 40 个字符来描述这个值是什么意思;
- QVAL:具体的数据值是多少;
- QORIG:这个值是如何获取的,比如 CRF(原始数据收集)、ASSIGNED(根据一些条件直接赋值)、DERIVED(通过计算和逻辑分类得到的);
- QEVAL:Evaluator,表示谁来完成的这次变量;
实战创建一个补充数据集 SUPPAE,以便加深理解:
data ae;
set data.ae_trtem;
if input(rfstdtc, yyddmm10.) <= input(substr(aestdtc, 1, 10), yymmdd10.) <= input(rfendtc, yymmdd10.) + 14 then trtem='Y';
else trtem='N';
run;
options validvarname=upcase;
data suppae;
retain studyid rdomain usubjid idvar idvarval qnam qlabel qval qorig qeval;
set ae;
rdomain = 'AE';
idvar = 'AESEQ';
idvarval = strip(put(aeseq, best.));
qnam = 'TRTEM';
qlabel = 'Treatment-Emergent Adverse Event';
qval = trtem;
qorig = 'DERIVED';
qeval = '';
keep studyid usubjid rdomain idvar idvarval qnam qlabel qval qorig qeval;
run;
自定义数据集
CUSTOM DOMAIN 自定义数据集。因为临床试验毕竟有一些不同,为了保留自由度,SDTM 提供了自定义数据集允许创建一些需要定义的数据集。
在创建自定义数据集时,需要遵守以下步骤:
- 仔细阅读 SDTM IG 文件,查看是否自己想要使用的变量内容确实无法归类到任何一个已经提供的标准数据集之中;
- 确定自己的数据集类别,是干涉类,发现类还是事件类,给自定义数据集搭建一个基本的框架;
- 找到每个类别中的几个数据集,找到共同存在的 required 变量,看看自己的数据如何放置在这些变量之中;如果实在无法容纳,就添加额外的变量。比如 LBFAST 变量表示是否空腹,如果你的数据集中也有需要表示是否空腹的变量,也需要使用 XXFAST 作为变量名。
同时在创建自定义数据集需要注意:
- 数据集命名以 XYZ 开头+两位大写字母,可以保证在所有标准数据集之后;
- 部分变量的命名依然需要遵守标准,比如 STUDYID 和 USUBJID;
- 不同分类的数据集的变量命名规则不同,比如干涉类里干涉的名称放在 TRT 变量中、事件类里事件名称放置在 TERM 和 DECODE 这两个变量中,发现类所有的测试名放在 TEST 变量中,测量值和单位放在 ORRES 和 ORRESU 中。
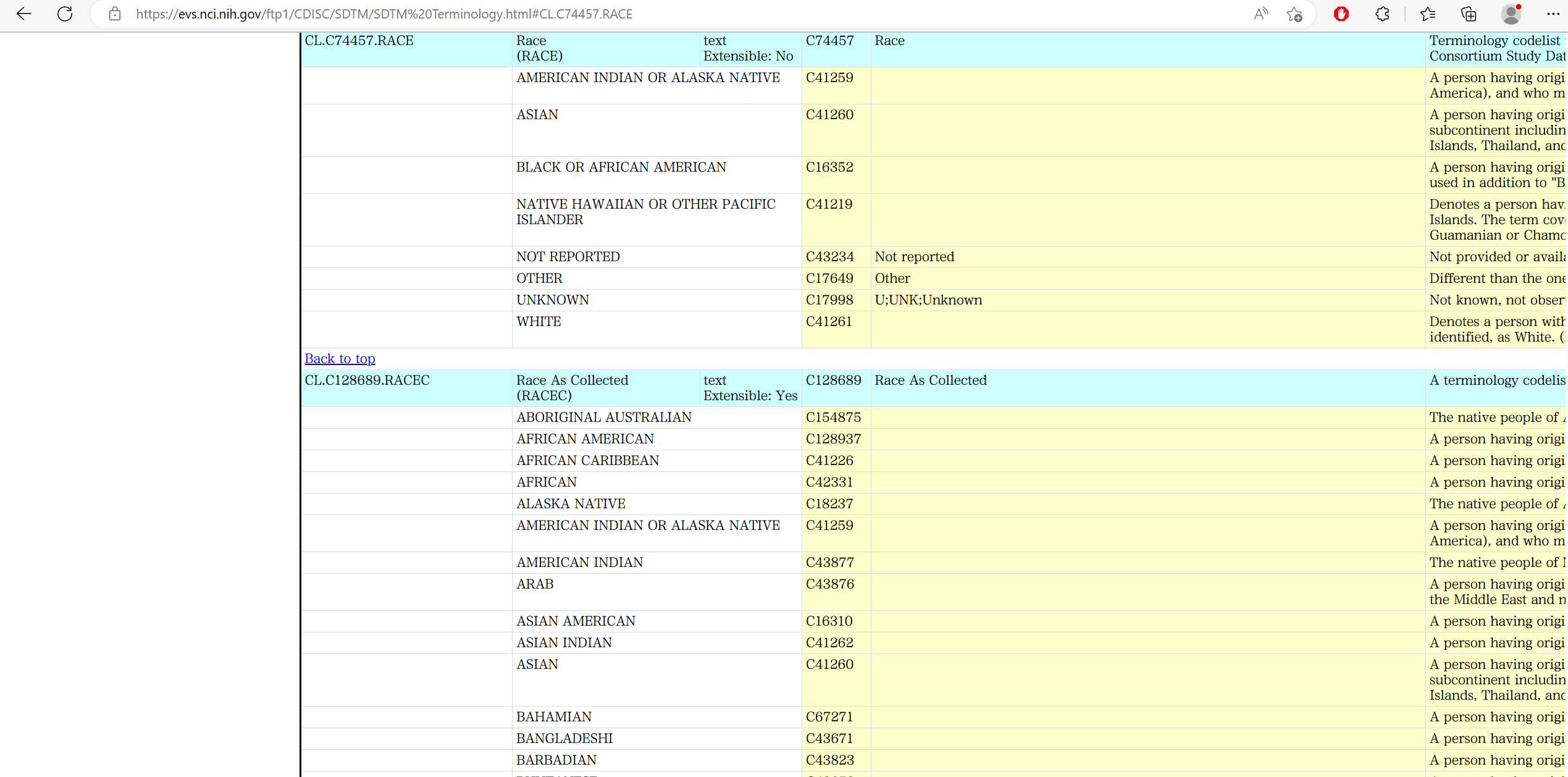
控制术语 Controlled Terminology
控制术语(Controlled Terminology) 是对 SDTM 里某些特定变量的值进行规范的一套规定。在查看 SDTM IG 的时候,经常会看到 Controlled Terms 这一项中有一些不为空的部分:
这就表示这个变量的值并不是我们想写什么就能写什么,必须按照给定的规范进行赋值。在 SDTM IG 文件中点击这些蓝色的链接,再结合搜索,就可以查看详细的规定: