CDISC 标准(三)——SDTM 标准初试
总结
- 第一次尝试仔细阅读 SDTM IG 文件中的一个 domain 变量信息;
- 通过 SAS 代码初试按照 SDTM 标准输出标准化的数据集。
本章要开始使用 SAS,并结合 SDTM 标准,看看如何让目标数据集符合 IG 文件里面的标准。
使用的目标 Domain 是 IG 文件 64-65 页介绍的,最重要的 Domain 之一—— DM Domain,具体变量说明表如下:
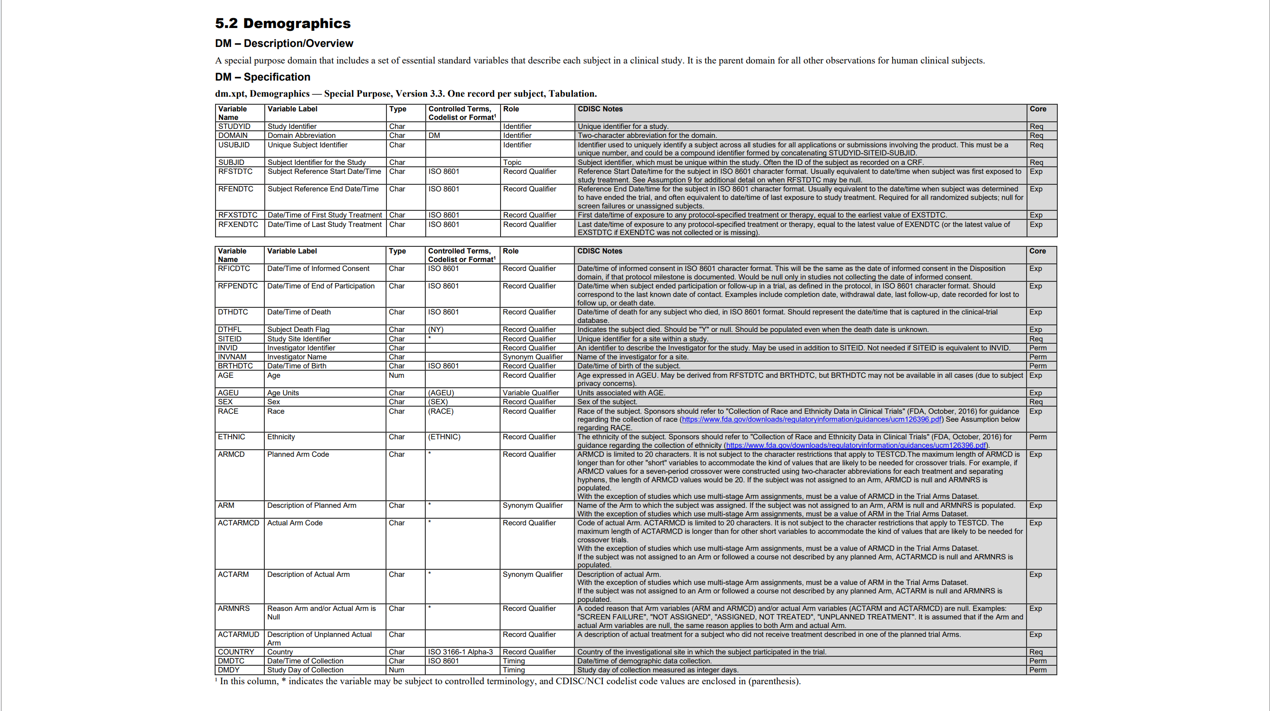
DM 是 Demographics 的缩写,代表人口统计学信息。所有人类参与的临床实验都需要 DM Domain,内容包括实验参与者的年龄、性别、种族、国籍、实验分组、实验开始日期和结束日期等等等等数据。
DM 数据集往往是接手某个项目最先阅读的数据集,可以查看和了解参与实验的患者的所有信息。在临床实验中,有几个患者参与,那么 DM 数据集中就需要包括几条观测数据。比如,有 10 名患者参与了临床实验,收集了原始数据,那么 DM Domain 中就应该包括 5 条观测。
接下来就是初学 SDTM 标准的学习方法:仔细阅读 SDTM IG 文件中对于每一条变量的说明,并且按照对应的要求,在 SAS 中处理数据集。处理过程中,需要注意以下几个重点:
- 注意每一条变量的 Type,字符型或者数值型,一定要在 SAS 中按照对应的格式存储,不符合的需要进行转换(
INPUT或者PUT); - 日期型的变量一定要注意按照规定的 ISO8601 格式;
- 变量顺序和变量的 Label 要按照表中规定的要求;
- 多多检查。
从 SDTM IG 表慢慢看起:
- STUDYID:实验的编号,每个临床实验都有的唯一编号;
- DOMAIN:固定取值 DM;
- USUBJID:患者的唯一编号,Notes 里写明了格式为 STUDYID-SITEID-SUBJID;
- RFSTDTC、RFENDTC:实验开始和结束的时间;在一些药物实验中,往往将患者第一次吃药作为实验开始的时间,将患者最后一次吃药为实验结束的时间;
- RFICDTC:介绍里是“date/time of informed consent”,代表患者正式签署或者参与临床实验协议的时间,往往也是收集到的第一个日期;
- RFPENDTC:参与的最后一个日期,往往是实验结束后跟踪随访的最后一次日期;如果患者出现失联或者去世等失访的情况,那就是失访前最后一次联系的日期;
- DTHDTC、DTHFL:和患者死亡相关,如果有死亡的患者,记录死亡的日期和 FLAG = Y;
- SITEID:研究站点/中心的编号;
- INVID、INVNAM:调查研究者的编号和名称;
- BIRTHDTC:患者的出生日期;
- AGE、AGEU:患者的年龄和年龄的单位(一般取值 YEARS);
- SEX 为性别,取值为 M 或 F;
- RACE、ETHIC:种族 / 是否为拉丁裔或者西班牙裔;
- ARMCD、ARM:计划的患者分组以及对应的描述;
- ACTARMCD、ACTARM:实际的实验分组以及对应的描述,根据实验要求可能不一样,需要仔细阅读 SAP 来决定;
- COUNTRY:国籍,要求里写明要遵守国际标准 ISO 3166-1,比如中国采用名称 CHN;
- DMDTC、DMDY:DM 数据是在什么日期收集的,距离实验开始有多少天。
接下来给出部分的进行 SDTM 标准的 SAS 代码:
libname learn "D:\CDISC标准\raw_data_files\";
* 完成 STUDYID, DOMAIN, USUBJID, SUBJID 的设置;
data dm1;
set learn.dmmr;
length studyid $10.;
studyid = 'XYZ-001';
domain = 'DM';
usubjid = strip(studyid) || '-' || strip(subject);
subjid = subject;
run;
* 完成 RFSTDTC RFENDTC 的设置;
data ex;
set learn.exto;
exdtc = put(input(compress(reportdt), date9.), yymmdd10.);
run;
proc sort data=ex;
by subject exdtc;
run;
data ex1 ex2;
set ex;
by subject;
if first.subject then output ex1;
if last.subject then output ex2;
run;
data dm2;
merge dm1 ex1(keep=subject exdtc rename=(exdtc=rfstdtc))
ex2(keep=subject exdtc rename=(exdtc=rfendtc));
by subject;
run;
* 完成 DTHDTC, DTHFL 的设定;
data dth1;
set learn.dth;
dthdtc = put(input(compress(dthdat_raw), date9.), yymmdd10.);
dthfl = 'Y';
keep subject dthdtc dthfl;
run;
* 完成 SITEID, BRTHDTC, AGE, AGEU, SEX, RACE, ARM, ARMCD, ACTARM, ACTARMCD, COUNTRY 的设定;
data dm3;
merge dm2(drop=siteid) dth1;
by subject;
*siteid = substr(subject, 1, 4);
siteid = scan(subject, 1, '-');
brthdtc = strip(put(brthdat_yyyy, best.)) ||'-'|| strip(put(brthdat_mm, z2.)) ||'-'|| strip(put(brthdat_dd, z2.));
age =.;age_raw='';
age = int((input(rfstdtc, yymmdd10.)-input(brthdtc, yymmdd10.)) / 365.25);
ageu = 'YEARS';
sex = substr(sex, 1, 1);
length race $50;
if american_indian = 1 then race = 'American Indian';
if asian=1 then race = 'Asian';
if black = 1 then race = 'Black';
if naticve_hawaiian = 1 then race = 'Native Hawaiian';
if white = 1 then race = 'White';
if other = 1 then race = 'Other';
length arm $20 armcd $8 actarm $20 actarmcd $8;
if substr(siteid, 1, 1) eq '1' then do;
arm = 'Treatment';
armcd = 'TRT';
end;
else if substr(siteid, 1, 1) eq '3' then do;
arm = 'Placebo';
armcd = 'PLA';
end;
actarm = arm;
actarmcd = armcd;
COUNTRY = 'CHN';
run;
* 规范 VARIABLE LABEL 以及变量顺序;
data dm4;
retain studyid domain usubjid subjid ......;
set dm3;
label studyid="Study Identifier";
domain="Domain Abbreviation";
......
