CDISC 标准(二)——SDTM 标准概述
总结
- 介绍了 SDTM 和 IG 文件的基本概念;
- 通过阅读 SDTM IG 文件,了解 Domain 和 Variable 的各种信息;
- 重点是 Variable 的五种分类:Identifier, Topic, Qualifier, Timing, Rule。
SDTM 的基本概念
SDTM(Study Data Tabulation Model)是一个服务于临床实验的标准数据指标模型,也是被业界和 FDA 广泛采用的标准。它规定了在临床实验中,原始数据收集之后的标准化的呈现方式。可能不同种类的药物,在实验中收集的数据样式是不一样的,但是经过 SDTM 标准化之后,相同类别的数据一定是相同的。
标准化的好处是,可以更好地服务于药物开发全链条中的各方人员,大大降低了沟通成本,提高审查部门的审核效率。经过多年的数次更新,SDTM 标准已经几乎可以涵盖所有类型的临床实验数据格式。
而 SDTM IG 文件(SDTM Implementation Guide)中就详细说明了所有 SDTM 标准化数据的方方面面的信息。想要了解 SDTM,就必须要从阅读 SDTM IG 文件开始。
从阅读 SDTM IG 文件开始
SDTM IG 文件可以从 CDISC 组织的官网中免费获得。官网下载得到的是英文版本,虽然民间存在个人翻译的中文版本,但还是推荐采用原汁原味的英文版本进行阅读。同时,官网还提供了 PDF 和 HTML 的多种格式,方便阅读。

Domain 域
在第二章 Fundamentals of the SDTM 中,向我们介绍了 SDTM 标准中的基础元素:Domain(域)。每个 Domain 可以理解为围绕一个主题,相关的所有观测和变量组成的数据集,其中有一些基础的通用要求:
- 每个 Domain 的名称都用两个大写字母表示;
- 举例:记录人口统计学的 Domain 名称为 DM,记录副作用的 Domain 名称为 AE;
- 每个 Domain 包括若干变量,绝大多数变量名称都以 Domain 的名称开头;
- 举例:副作用的 Domain AE 下的大部分变量以 AE 作为开头。
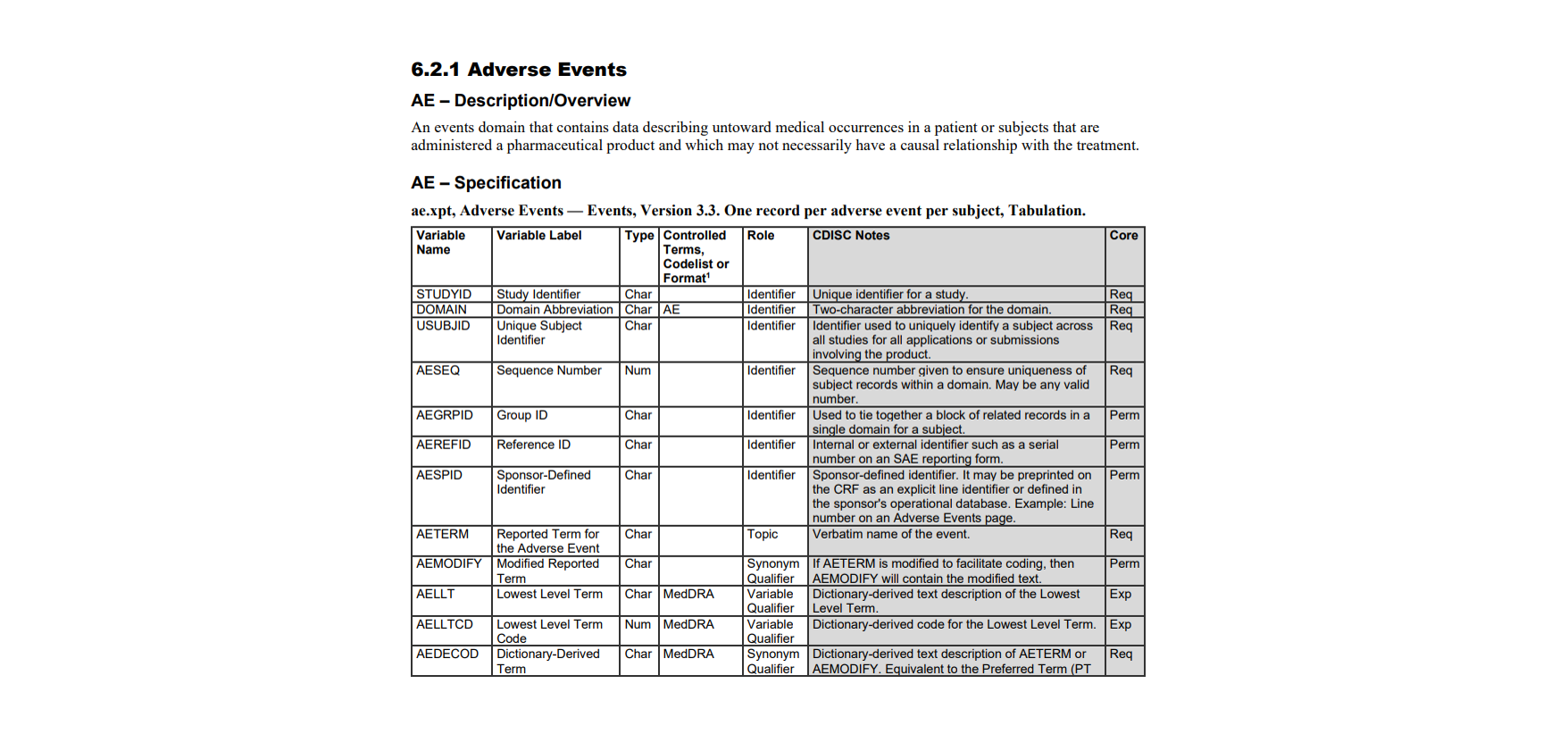
Variable 变量信息
从 IG 文件中可以看到,每个 Domain 中都存在若干变量,并且有一个变量说明表,从左到右依次是变量名称,变量标签,存储的数据类型,取值范围,变量类型,变量意义说明,变量存在度要求。接下来对这些基本概念进行介绍,就可以基本看懂不同 Domain 的变量表。
变量也有几个的通用要求:
- 每个变量名称(Variable Name)总长度是 8 位;
- 每个变量有标准化的标签(Variable Label),长度是 40 位;
- 可以看到 Type 列,表示变量的存储类型要求,在 SAS 中只有两种存储类型:Char 代表字符型,Num 代表数值型。
SDTM 标准下的变量可以分为 5 个大类,可以看到上图中的 Role 那一列:
- Identifier:用于标识和编号,比如研究 ID,患者 ID 等,举例 STYDYID(实验编号),USUBJID(患者唯一标识 ID 号码);
- Topic:上面提过,一个 Domain 的核心内容,举例 AE Domain 中的 Topic 就是副作用相关变量;
- Qualifier:修饰作用,对于 Topic 内容的补充说明,也包括以下几类:
- Grouping Qualifier:表示分类的说明,举例 LB Domain(实验室检测域)中的 LBCAT 代表检测类别(血检 / 尿检);
- Synonym Qualifier:对 TOPIC 的一个修饰,举例 LB Domain 中的 LBTEST 表示对检测名称的说明;
- Record Qualifier:对某条记录的说明,举例 LB Domain 中的 LBBLFL 代表这条记录是否是基准线值(如果为 Y 代表是基准线值);
- Result Qualifier:表示结果的内容,举例 LB Domain 中的 LBORRES 代表检测结果;
- Variable Qualifier:对某些变量的修饰,举例 LB Domain 中的 LBORRESU 代表检测结果的单位;
- Timing:表示日期和时间相关的变量,字符型变量格式,必须按照 ISO8601 的格式:yyyy-mm-ddThh:mm:ss;
- 每一个日期都必须对应一个从实验开始计算的时间差,用数值型存储,举例 AE Domain 中 AESTDTC 表示副作用开始的时间,AESTDY 就是副作用在实验开始后的第几天产生;
- Rule:规则相关的变量,主要放在实验设计相关的 Domain 中。
另外,IG 文件中变量表的最后一列 Core 代表对变量存在度的要求,分为以下三类:
- Req:代表 Required,指这个变量必须存在;
- Exp:代表 Expected,比 Req 低一级,表示希望存在的变量,没有也可以;
- Perm,代表 Permissible,代表允许存在的变量,是否添加到数据集中要看实验设计。
注意,SDTM 标准下只允许规定的变量存在于数据集中。收集到的数据变量如果在 SDTM 标准中没有,一定不能添加到 SDTM 数据集中。每个数据集变量必须存在于 IG 中,只能少,但是不能多。
SDTM 放不进去的数据怎么办
虽然 SDTM 在逐步更新的过程中,基本上能够覆盖到超过 90% 的常见临床实验的情况。但毕竟每一款药物都有自己特殊的地方,有可能遇到某一些变量无法放置在 SDTM 标准数据集的情况,这时候要介绍两个概念:补充数据集和自定义数据集。
如果数据是某些 SDTM domain 的补充内容,就放置在补充数据集中。
- 补充数据集的命名要求:SUPP + 原始 SDTM Domain 名称;
- 举例:关于心电图的 Domain EG,医生对于心电图的解读结果无法放在标准化的 EG 数据集中,就可以放置在命名为 SUPPEG 的补充数据集中;
- 注意“追溯性”:补充数据集中的每一条数据必须在原始数据集有对应记录。
而如果某一种数据,无法归类在 SDTM 标准下的任何一个 Domain,就要使用自定义数据集了,这一类型的命名要求是:XYZ + 两位字母。不过这种情况极为极为少见,如果真遇到这种情况,还是好好检查一下,看看自己是不是遗漏了 IG 文件中的某个 Domain。
