数据挖掘的奇效——爬到网站没有显示的数据
有没有想过,有些网站的页面上展示的数据只有一部分的时候,通过稍微一点挖掘就能发现额外的数据,收获更多信息。
这里就举一个最近发现的例子——云顶之弈公开赛“云巅赛道”的官方实时排名更新。 可以看到,这里只展示了云巅赛道前 60 名的用户昵称、段位、胜点、排位场数、登顶率和前四率。
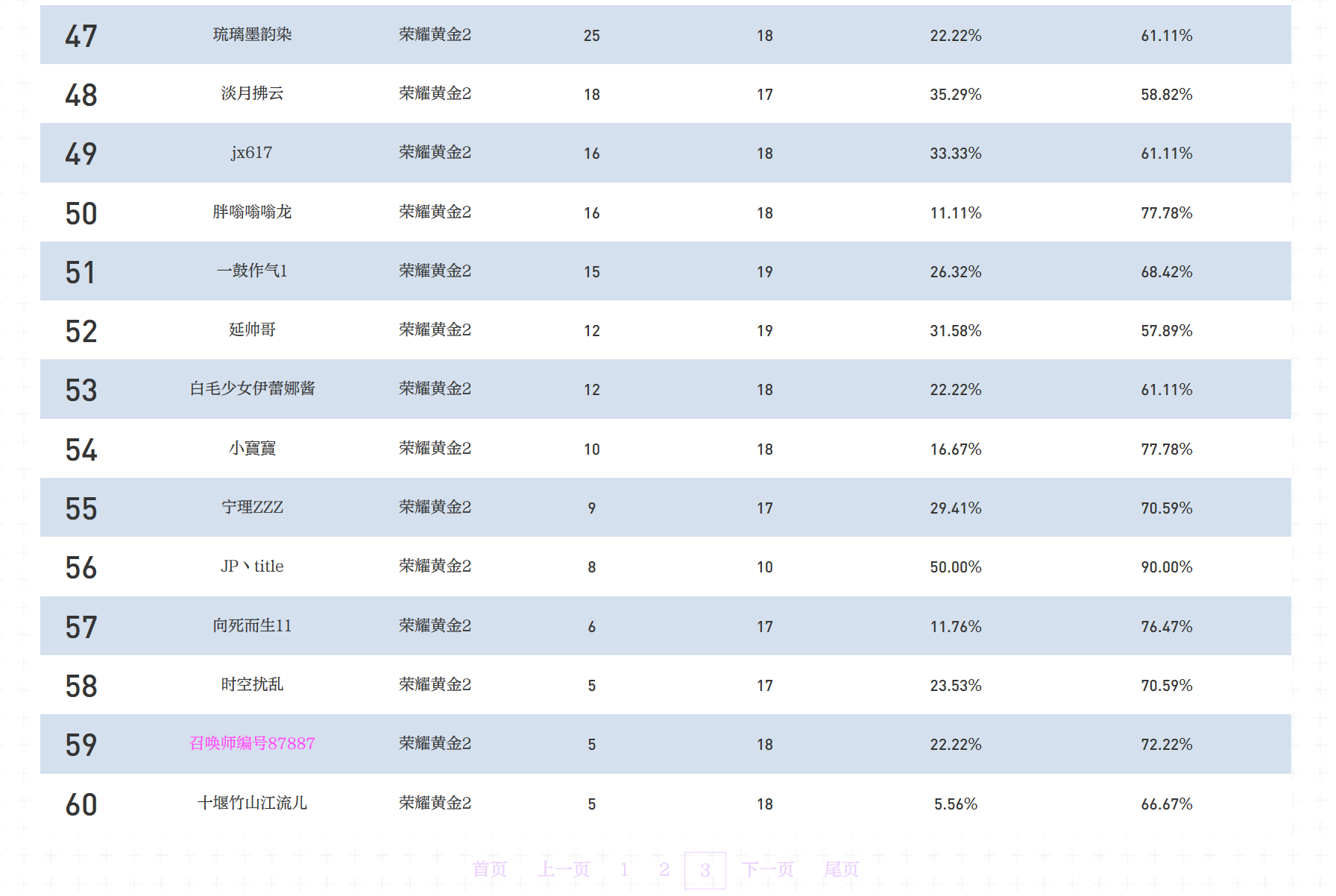
但是其实,只要扒到网站请求的数据,兴许可以看到更多的数据。
发现网站请求返回的数据
这里其实没有想象中那么难。在「检查」中的「网络」选项卡查看网站的请求,一眼就能发现这个全是大写的请求返回的 json 数据。 稍微看一下,各类数据也都对的上,就是这个了:
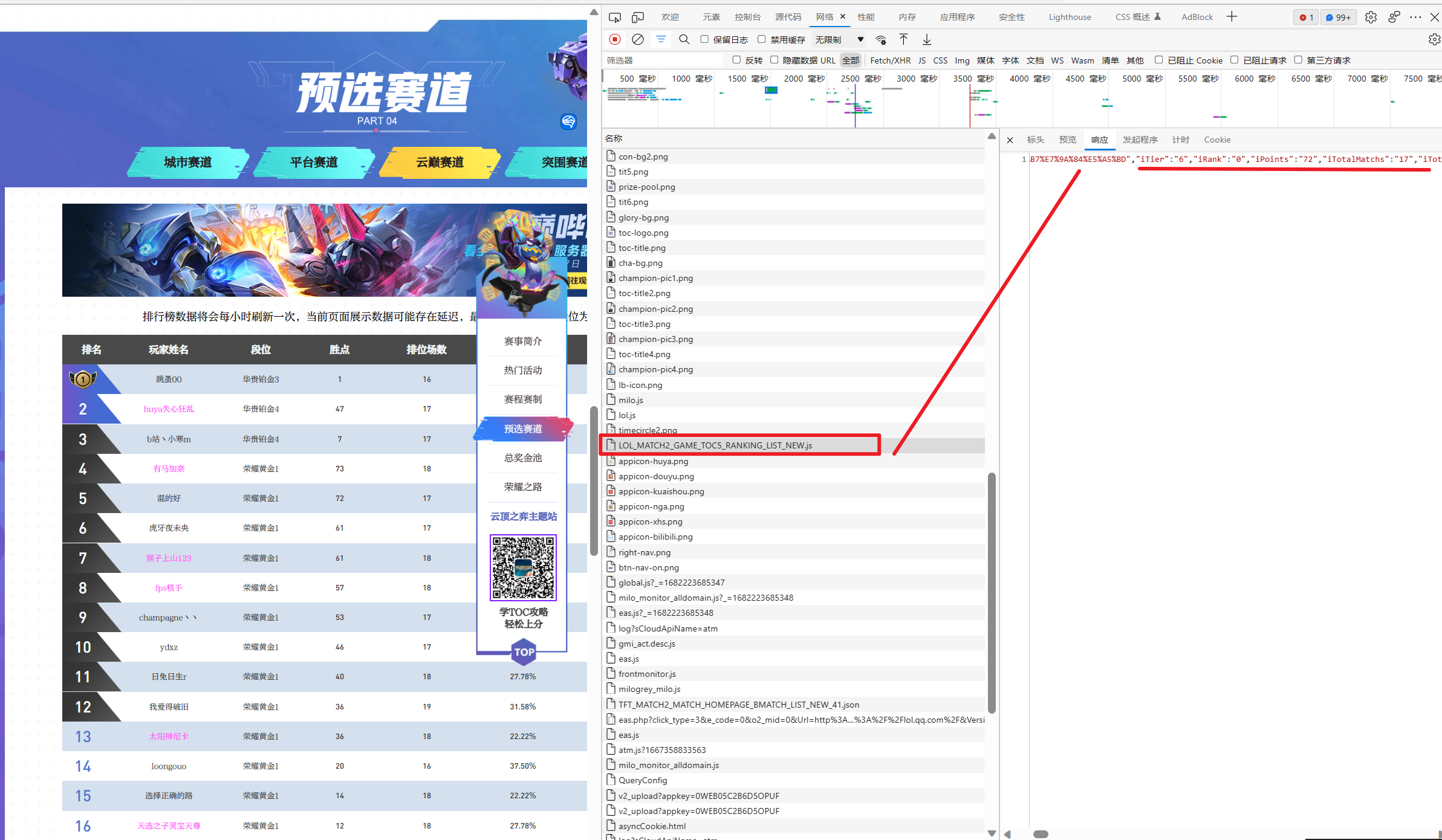
这里可以复制请求链接,再每隔一段时间请求一次,查看实时更新变化,我这里就不做了,有兴趣的可以查看我的另一篇文章。我就直接将 json 数据保存到了本地。
使用 RJson 解析 json 格式数据
这里就使用一下 R 语言中的 RJson 包来解析一下 json 格式数据:
library(rjson)
result <- fromJSON(file="云巅.json")
result
可以看到,直接使用 fromJSON 读取出来的是 list 格式的数据,还是多次嵌套的 list:
- 第一层:每一个用户作为一层;
- 第二层:单个用户下的每一个变量数据作为第二层;
同时,可以看到,最关键的用户名 sName 变量用了 URL Code 编码,需要再使用 URLdecode 解一下。

这就需要先进行多层 list 数据的解包,加上稍微一点预处理了:
library(tidyverse)
# 将 json 数据的每一层(每一个用户)转换成单行数据
row_results <- lapply(result[[2]], function(x) {
as_tibble(x)
})
# 对单行数据进行合并,得到最终数据
toc_rank_result <- do.call("rbind", row_results)
# 使用 URLdecode 转换用户昵称
toc_rank_result <- toc_rank_result %>%
mutate(nickname = URLdecode(sName)) %>%
select(nickname, iTier, iRank, iPoints)
# 查看转换后的数据
View(toc_rank_result)
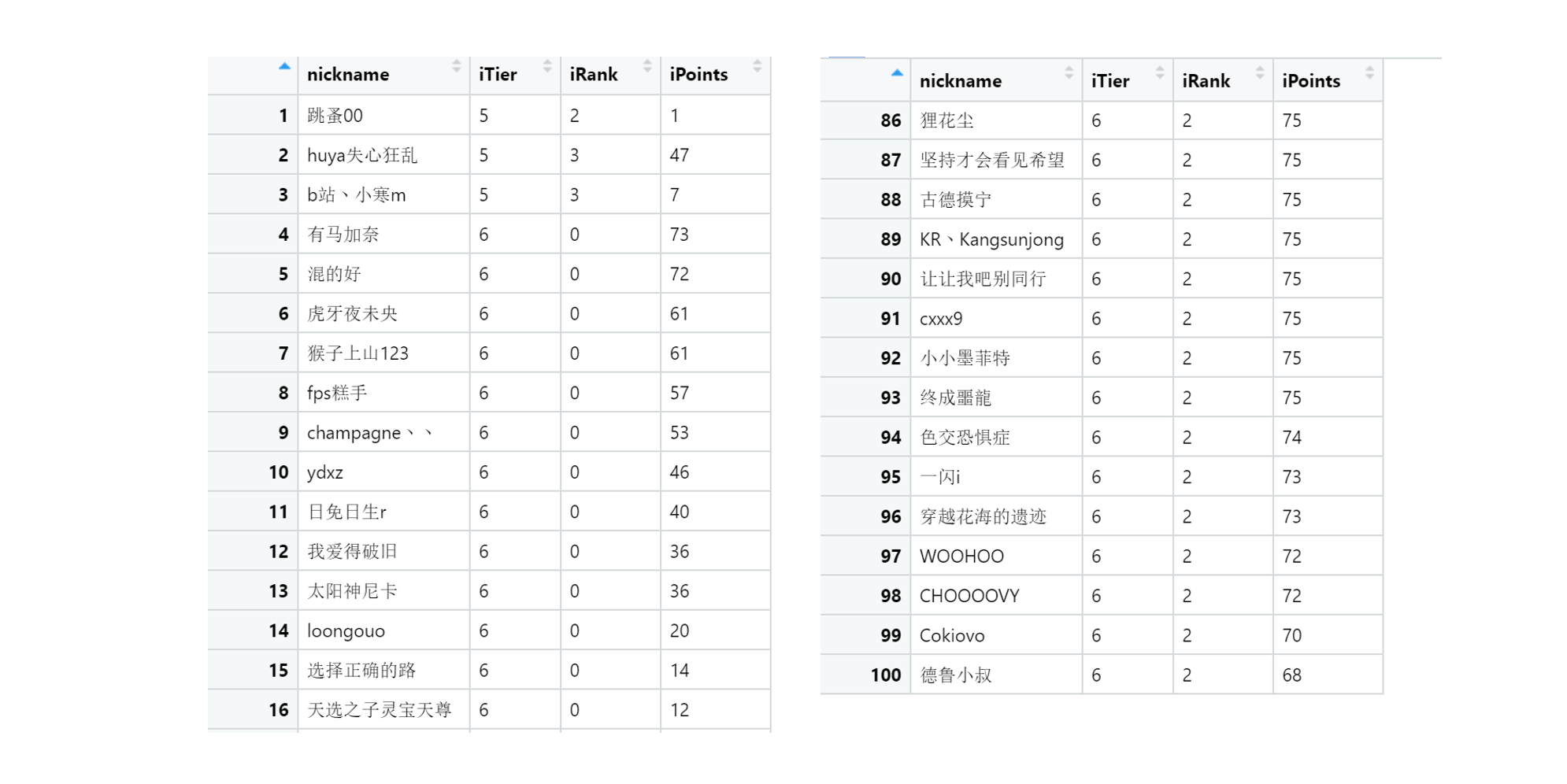
大功告成!可以看到,相比于官网页面上的 60 条数据,这里分析的请求数据总共有 100 条,足足多了 40 条。 而且爬下来的数据想要做更多的查询和分析也更加方便了。 有时候,网页上没有显示的数据,可能还真需要扩展一下思路,看看能不能用其他方法得到。
