动态页面的爬虫示例一则:抓取微博粉丝列表
在碰到一些网页,想通过爬虫抓取页面信息的时候,会发现网页采用了一些动态 HTML 的相关技术来展示信息。这样直接使用 requests 是无法直接获取想要的 HTML 元素内容的。比如我们查看微博网页端的粉丝列表:
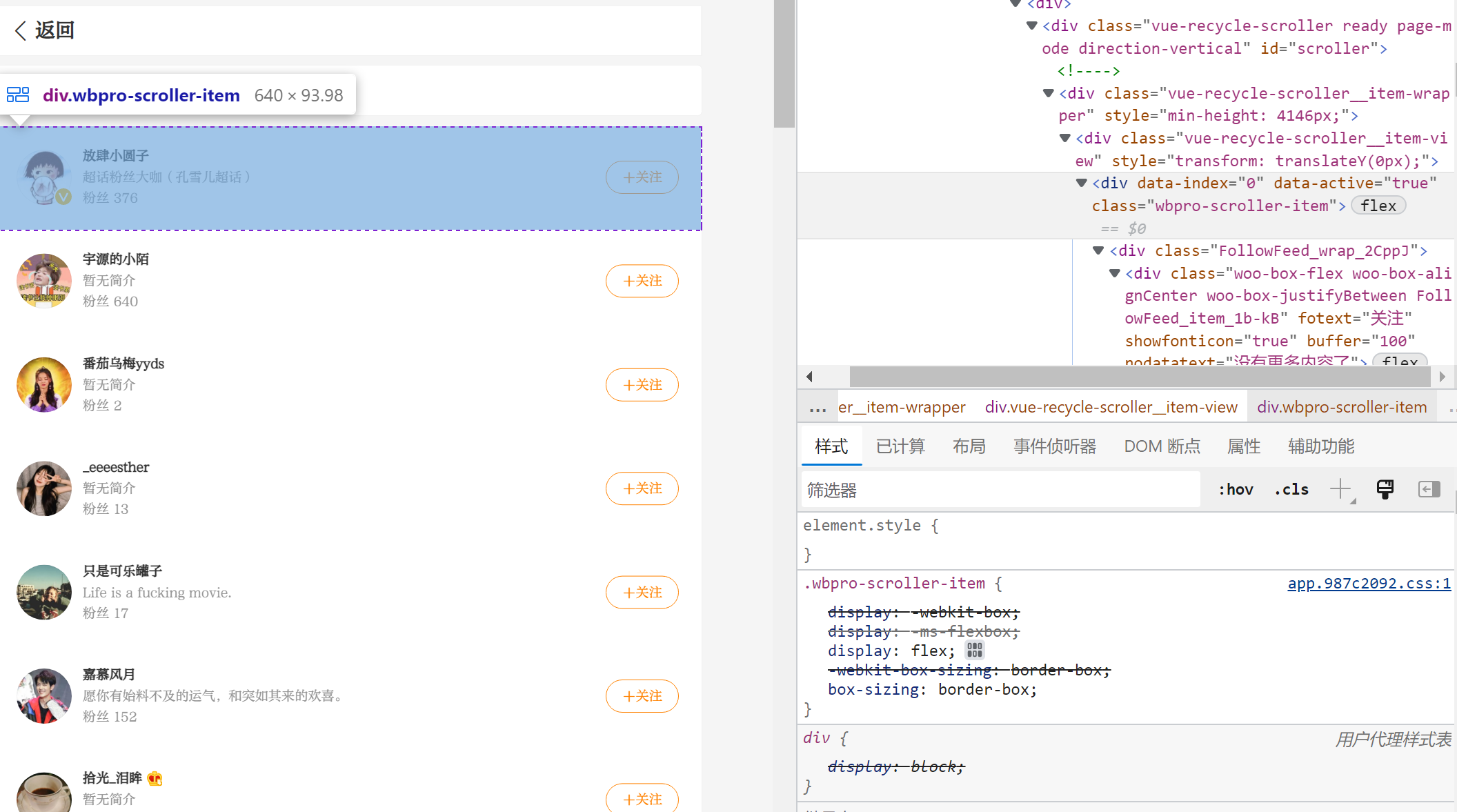
微博网页端的粉丝列表,在向下刷的时候是会动态加载和更新的。这种情况下,我们想要的元素是通过 js 事件动态请求和返回的。那么,就需要我们分析页面请求,找到那个发送的请求和对应返回的数据。在 F12 的「网络」选项卡下面进行刷新,可以比较轻松地找到对应发送的请求和返回的数据(json 格式):
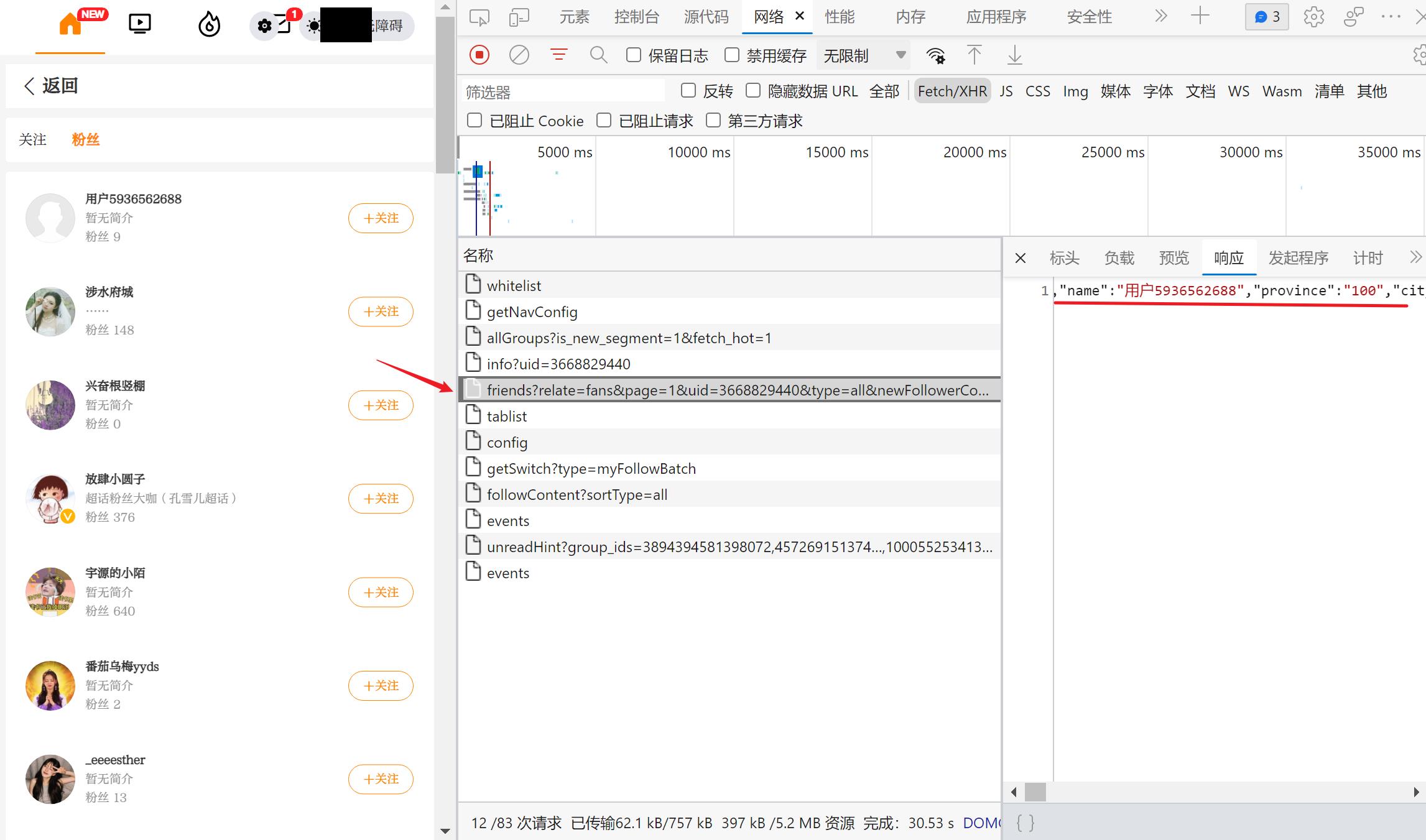
可以看到,这个请求会返回 json 格式的数据。当用户下拉粉丝列表页面时,会触发一个 js 事件,项服务器发送这个请求获取数据,再通过一定的逻辑将这些 json 数据填充到 HTML 页面中。而我们的爬虫只要获取这些 json 数据,再进行整理就可以了。
这样一来就比较轻松了:(当然需要注意一下,发出的相关请求需要你保持登录的 Cookie,不然返回会报错)
import requests
headers = {
'cookie': 'Your Cookie',
'User-Agent': 'Your User Agent',
'referer': 'Your referer'
}
url = "https://weibo.com/ajax/friendships/friends?relate=fans&page=1&uid=3668829440&type=all&newFollowerCount=0"
r = requests.get(url, headers=headers).json()
for user in r['users']:
print("id: {} - name: {} = fans:{}".format(user['id'], user['screen_name'], user['followers_count']))
当然,我们可以看到 url 里面的参数 page=1,那么我们可以修改这个参数就可以获得很多页面的粉丝列表信息了。再保存到准备好的数据库中:
import requests
import pymysql
# 连接 MySQL 数据库
conn = pymysql.connect(
host='127.0.0.1',
user='root',
passwd='your pwd',
port=xxxx,
db='your db',
charset='utf8'
)
headers = {
'cookie': 'Your Cookie',
'User-Agent': 'Your User Agent',
'referer': 'Your referer'
}
# 每次查看并更新 10 页粉丝列表
for page_i in range(10):
url = "https://weibo.com/ajax/friendships/friends?relate=fans&page={}&uid=3668829440&type=all&newFollowerCount=0".format(page_i)
r = requests.get(url, headers=headers).json()
for user in r['users']:
name = user['name']
screen_name = user['screen_name']
followers_count = user['followers_count']
followers_count_str = user['followers_count_str']
# 如果粉丝数超过 10000,进行播报
if followers_count >= 10000:
print("新增过万粉丝播报:id:{} - name:{} - fans:{}".format(user['id'], screen_name, followers_count))
sql = f"""
insert ignore into your_table
(user_id, name, screen_name, followers_count, followers_count_str)
values('{user['id']}', '{name}', '{screen_name}', '{followers_count}', '{followers_count_str}');
"""
cursor = conn.cursor()
cursor.execute(sql)
conn.commit()
add_fans_count = after_update_fans_count - before_update_fans_count
print("本次新增查询粉丝数:{}".format(add_fans_count))
print("数据库中已存储粉丝数:{}".format(after_update_fans_count))
conn.close()

当然,这只是爬一个单独的账号的粉丝列表(我喜欢的一个明星)。一般而言,不用实时监听,只需要每隔一段时间爬取一次,就能更新最近新关注的用户,并且发现是否有粉丝数过万的大V。需要注意的一个问题是,每隔一段时间(2-3天)就需要更新一下 Cookie,不然也会报错。
以上内容供大家参考,共同学习。
